Teaching modeling in introductory statistics
A comparison of formula and tidyverse syntaxes
Amelia McNamara @AmeliaMN
Pre-print
This talk is based on a paper I wrote, which is available as a pre-print via arXiv, https://arxiv.org/abs/2201.12960

Palmer Penguins

Penguin data and penguin art by Allison Horst.
Summary statistics three ways
base
formula
tidyverse
Scatterplot three ways
base
formula
tidyverse
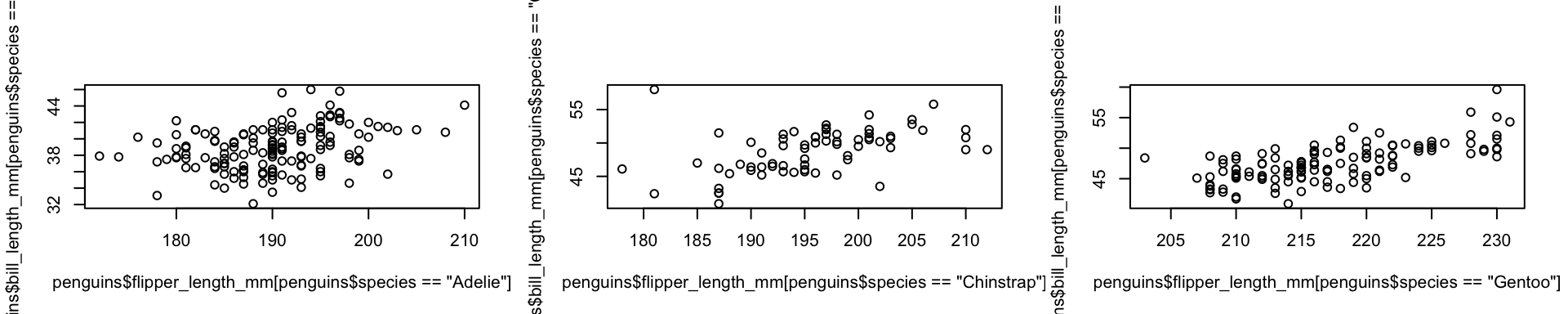
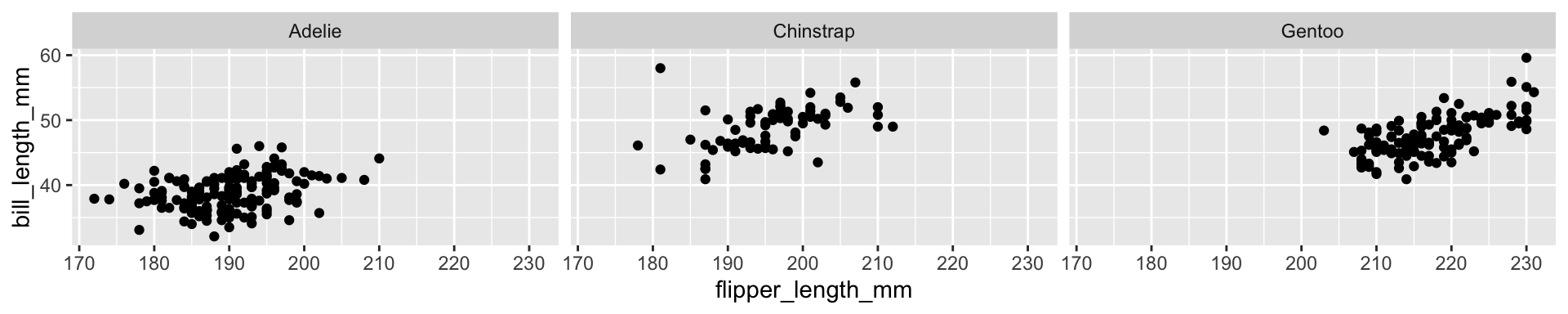
Sets of scatterplots three ways
base
par(mfrow = c(1, 3))
plot(penguins$flipper_length_mm[penguins$species == "Adelie"],
penguins$bill_length_mm[penguins$species == "Adelie"])
plot(penguins$flipper_length_mm[penguins$species == "Chinstrap"],
penguins$bill_length_mm[penguins$species == "Chinstrap"])
plot(penguins$flipper_length_mm[penguins$species == "Gentoo"],
penguins$bill_length_mm[penguins$species == "Gentoo"])
# apply solution?formula
tidyverse
Sets of scatterplots three ways
base
formula/tidyverse
Choosing syntax
There is debate in the statistics education community about which syntax is best to teach, particularly for the “first course.” All three syntaxes have their proponents, but the folks most interested in pedagogy tend to argue about whether formula or tidyverse is best.
- the base first philosophy typically comes from people who were taught base first, often using the man page for R. Jeff Leek has argued for the use of base graphics but very few arguments for base-first are grounded in pedagogy
- tidyverse first philosophy, as espoused by Mine Cetinkaya-Rundel, Jo Hardin, Ben Baumer, myself, Nick Horton, and Colin Rundel in An educator’s perspective on the tidyverse.
- formula first philosophy, “the third way”, as laid out by Nick Horton. This philosophy led to the
mosaicpackage, which Horton coauthored with Randy Pruim and Danny Kaplan.
Head-to-head comparison
- Students enrolled in the same lecture class (60-90 students)
- Lecture was broken into three smaller sections for lab material
- I taught two of the sections (n=21 in each), and both were designated as using R
- Using random assignment (coin flip) I chose one to use
tidyversesyntax and one to use formula syntax - Similar students in both groups– mostly business majors, similar prior programming experience
| formula | tidyverse | |
|---|---|---|
| No | 10 | 9 |
| Yes, but not with R | 2 | 4 |
Why do this?
To get some data
Constraints breed creativity
Data
I was able to gather lots of data:
- RMarkdown documents and associated code
- Pre- and post-survey
- YouTube analytics
- RStudio Cloud analytics
getParseData()
The getParseData() function from utils allows you to parse R code and find all sorts of things about the parse tree. I just filtered for functions.
Minimal reproducible… stats course
Like “Enough R for Intro Stats” by Randy Pruim.
The formula section saw a total of 37 functions and the tidyverse section saw 50, with an overlap of 18 functions between the two sections.
Neither of these numbers are very large!
The functions both sections of students saw included helper functions like library(), set.seed(), and set() (a function in the knitr options included in the top of each RMark- down document), statistics like mean(), sd(), and cor(), and modeling-related functions like aov(), lm(), summary() and predict().
What was hard? (formula edition)
Dealing with missing data.
Solutions:
- More consistency in prep.
- Teach some wrangling
- ??
What was hard? (tidyverse edition)
Explaining things with two categorical variables (two-way tables, inference)
For comparison
2-sample test for equality of proportions with continuity correction
data: tally(island ~ sex)
X-squared = 2.8876e-30, df = 1, p-value = 1
alternative hypothesis: two.sided
95 percent confidence interval:
-0.1248439 0.1147680
sample estimates:
prop 1 prop 2
0.5673759 0.5724138 Pre- and post-survey
Not much difference between sections

Pre- and post-survey

Pre-lab length
RMarkdown documents, in lines

pre-lab videos, in minutes

Compute time

Model
Fit a linear mixed-effects, using month as a categorical variable. lme4 package doesn’t provide p-values, but we can look at confidence intervals.
| 2.5% | 97.5% | |
|---|---|---|
| .sig01 | 3.3 | 6.1 |
| .sigma | 4.5 | 5.9 |
| (Intercept) | 8.4 | 14.4 |
| sectiontidyverse | -6.2 | 2.2 |
| monthOctober | 1.2 | 7.5 |
| monthNovember | -4.9 | 1.5 |
| monthDecember | -5.5 | 0.9 |
| sectiontidyverse:monthOctober | 0.4 | 9.4 |
| sectiontidyverse:monthDecember | 0.7 | 9.7 |
So, which should I use?
It depends!
I used formula this past semester when I taught the R labs again. Most students won’t go on to another stat class, and are mostly “users” of R rather than “doers.”
If most of my students were stat majors, I would definitely teach tidyverse. If it was intro data science, I would teach tidyverse.
My big suggestion is be consistent.
Constraints breed creativity!
Use getParseData() to learn how many functions you are using, and streamline.
Learn more
- Pre-print https://arxiv.org/abs/2201.12960
- Reproducible code to generate paper https://github.com/AmeliaMN/ComparingSyntaxForModeling
- Pre-lab documents and cheatsheets https://github.com/AmeliaMN/STAT220-labs